Editing NeRFs
NeRFs can generate 3D views easily; how can we use the architecture to improve the experience?
Neural Radiance Fields is a method of visual rendering, powered by MLPs, that I have been researching for the past few weeks, and have done my own research project on for a graduate machine learning class. Please take a look here for my rundown of the NeRF paper.
A benefit of NeRFs being continuous, view-depending functions is that they practically act as shaders. They take in 5D data about each voxel in a 3D space and use ray marching, and output information to construct a 2D image plane. As they act like shaders, using diffusion models is a popular avenue of modifying NeRFs, such as materials editing and removing objects, while maintaining good persistence and continuity of the scene. The following papers were the basis of my project, which also looked into using diffusion models to aid NeRF generation.
Instruct NeRF2NeRF
Paper: https://arxiv.org/pdf/2303.12789.pdf

InstructPix2Pix is a popular Stable Diffusion pipeline that takes in an image prior and passes it through a conditional diffusion model, editing the image based on prompt instruction. This creates an image that is edited but maintains a similar image structure of objects, composition, and colors. This is often used hand-in-hand with ControlNet, which is a framework that helps diffusion models base generations off of geometric and pose priors.
What InstructNeRF2NeRF does is take a pre-trained reconstructed NeRF scene, a text instruction, and the source data (original images and camera poses) as input, iteratively update image content at the captured viewpoints with the help of IP2P and consolidate the edits in 3D through NeRF training.
To edit the images, they take a noisy version of a render from a viewpoint and use a DDIM process to gradually remove noise from an image while preserving its structure and information. DDIM stands for denoising diffusion implicit models, an iterative implicit probabilistic model with the same training procedure as DDPMs, which is a non-Markovian diffusion process that leads to the same training objective, but with a reverse process that can be much faster to sample from. This process allows for the generation of high-quality images with fine details and textures and is computationally efficient and parallelizable. Additionally, the diffusion model is conditioned on unedited images, which allows the structure to remain grounded.
To update the NeRF, the team used an iterative dataset update method. In each iteration, there are a certain number of image updates and a certain number of NeRF updates. The editing process results in a sudden replacement of dataset images with the edited counterpart. Images may be inconsistent at first, but they converge on a globally consistent depiction as images are used to update the NeRF and progressively rerendered. This iterative process helps maximize the diversity of training gray viewpoints, and improves the stability and efficiency of training.
However, there are still some edits that fail to consolidate or be edited well, such as in object removal as well as with complex patterns.
Removing Objects from Neural Radiance Fields
Paper: https://nianticlabs.github.io/nerf-object-removal/resources/RemovingObjectsFromNeRFs.pdf

Sometimes in NeRF captures, you would want some objects to be removed, such as confidential or personal items. Niantic Labs developed a method of removing objects from NeRFs using inpainting.
Inpainting is the process of filling in missing or corrupted parts of an image, and in the context of NeRFs, it involves removing unwanted objects from the scene by inpainting them with the surrounding background. The Niantic team’s method leverages existing 2D single-image inpainting techniques to paint each RGB image individually, assuming a given RGB-D sequence with camera pose and intrinsic. This can be obtained using a dense structure-from-motion pipeline.
The team also introduced a depth inpainting network to fill in the gaps left by removing objects from the scene. Both the RGB and depth inpainting models are treated as black boxes, meaning that improvements to either model could be incorporated into the method.
One issue that arises with this approach is that the inpaintings are sometimes not multiview consistent. This means that when looking at the same part of the scene from different viewpoints, the inpainted regions may not match up, leading to inconsistencies in the final NeRF model. To address this, the team developed a new confidence-based view selection scheme that iteratively removes inconsistent inpaintings from the optimization.
The scheme works by associating each image with a non-negative uncertainty measure, which is used to reweight the NeRF losses. The RGB loss is calculated, and the second term of the loss equation is only applied to a restricted set of pixels, which means that only some inpainted regions are used in the NeRF optimization.
To enforce multiview consistency, the team modeled multiview inconsistencies using viewing direction and introduced an auxiliary network head that does not take the viewing direction as input. This forces the model to encode inconsistencies between inpaintings while keeping the model consistent across views. The process is repeated iteratively, with non-confident images being removed and NeRF being retrained until the desired level of accuracy is achieved.
NeRFBusters: Removing Ghostly Artifacts from Casually Captured
Paper: https://arxiv.org/pdf/2304.10532.pdf

The paper “NeRFBusters” addresses the problem of floating artifacts in NeRFs. These artifacts appear in casual captures of NeRFs due to poor data in the captures, leading to bad geometry and noise. While several methods have been developed to mitigate these artifacts, they focus on evaluating image quality at held-out frames rather than at novel viewpoints.
The NeRFBusters approach involves two steps: first, a diffusion model is trained to learn the distribution of 3D surface patches. Second, this local prior is applied to NeRF reconstruction of real 3D densities.
The local prior is formulated as a data-driven 3D prior and is trained on local cubes sampled from ShapeNet. The diffusion model iteratively denoises a voxelized 32x32x32 cube of occupancy. The synthetic 3D cubes are curated to train the diffusion model.
To apply the 3D prior in the wild, the researchers use cube importance sampling. Since NeRF represents a density field, cubes of occupancy can be queried in 3D space at any size, location, and resolution. A low-resolution grid of either accumulation weights or densities is stored for efficiency. This grid informs the probability with which to sample different positions in the scene.
The researchers use Density Score Distillation Score (DSDS) loss to regularize the sampled density. The diffusion model is trained on discretized synthetic data in 1, indicating free/occupied space. NeRF densities are [0,inf), and densities < 0.01 are usually free space, while occupied usually has values [0.01,2000]. The NeRF densities are discretized into xt = 1 if sigma > tau else -1 for timestep t, where tau is a hyperparameter for deciding if a voxel is empty or occupied.
The diffusion model predicts the denoised cube and penalizes NeRF densities that the diffusion model predicts as empty, increasing densities that the diffusion model predicts as occupied. The DSDS does not add noise to the original sampled occupancy before providing it to the diffusion model.
The researchers use a frustum check to approximate the visibility of a 3D location in another training view, taking the sum. This simple regularizer is effective in removing floaters from regions outside the convex hull of training views.
NerfDiff
Paper: https://arxiv.org/pdf/2302.10109.pdf
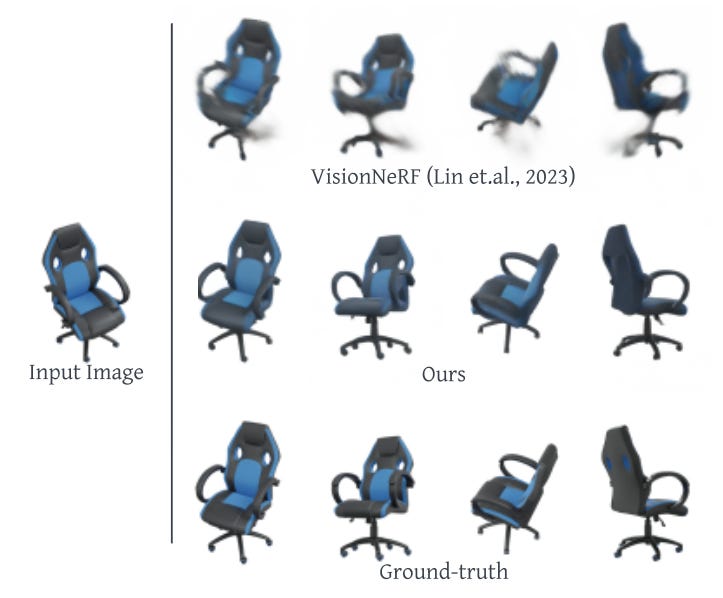
NeRFs require tens or hundreds of images to overfit a scene and have no generalization ability to infer new scenes. Additionally, the uncertainty of large unseen regions in novel views cannot be resolved by projection to the input image, which works well for smaller regions. To address these issues, a new approach called NeRFDiff has been proposed, which jointly trains a camera-space triplane-based NeRF and a 3D aware conditional diffusion model (CDM) on a collection of scenes, so that NeRFs can be generated from a limited amount of input images.
The CDM in NeRFDiff is a generative model that conditions other variables/priors to synthesize a target variable of diffusion convergence. The NeRF is initialized using input images during the finetuning stage, after which the parameters are fine-tuned from a set of virtual images predicted by the CDM conditioned on the NeRF-rendered outputs. However, the naive finetuning strategy of optimizing the NeRF parameters directly using CDM outputs can lead to subpar renderings and multi-view inconsistency. To address this, NeRFDiff proposes a NeRF-guided distillation approach that updates the NeRF representation and guides the multiview diffusion process in an alternating fashion, resolving the uncertainty in single-image view synthesis by filling in unseen information from the CDM.
The NeRFDiff process begins with a single image NeRF with Local Triplanes that shape the image feature W into a camera-aligned triplane (Wxy, Wxz, Wyz). Each 3D point receives a unique feature vector by bilinear interpolation within three planes, allocating depth information without any additional positional encoding needed. This approach can naturally preserve local image features and does not require assuming global coordinate systems or global camera poses.
Next, a 3D aware conditional diffusion model is modeled as the second part of NeRFDiff to resolve uncertainty through a generative process. The CDM iteratively refines the rendering of single-image NeRF to match the target views, avoiding alignment problems by applying single-image NeRF to render target view images as the conditioning to CDM rather than using input view images as conditioning.
During the fine-tuning phase, the CDM’s knowledge is distilled using a NeRF-guided distillation approach. The naive optimization strategy of replacing targets with virtual views sampled from the CDM is noisy, so the approach alternates between NeRF distillation and diffusion sampling. This approach incorporates 3D consistency to multiview diffusion by considering the joint distribution for each virtual view.
There are some limitations to NeRFDiff. At least two views are required, and the finetuning process is expensive and time-consuming. Nonetheless, NeRFDiff shows promising results in generating high-quality novel views from limited image inputs.
Overall, the research in using diffusion with NeRFs and taking advantage of the continuous function nature of NeRFs helps with overall flexibility and accessibility to generating and modifying 3D captures. Applications like Luma’s Unreal Engine plugin are already making their way to gaming, and Google is implementing NeRFs into Google Maps and shopping; I can definitely see the technology making its way into many other industries in the coming months as NeRFs become faster, more accurate, and easier to modify.