Quadtrees overview
graphic's favorite datastructure
When given a large corpus of organizable data, one common data structure we use in databases, programs, and algorithms is the binary tree. A binary tree consists of a parent→child node structure, where each node, starting from the root (topmost node), can be a parent to a maximum of two child nodes. Each node without a child is called a “leaf.” One use case of a binary tree is spatial partitioning; starting from the top level node, with the largest range possible for the dataset, a program can traverse downwards, increasing the definition of the dataset each level, until it reaches the leaf nodes.
Quadtrees (and N-D trees) take advantage of this utility from a binary tree to N-dimensional spatial partitioning (for N≥2) in computing areas such as spatial data storage, geohashing, graphics, and game engines. Quadtrees are similar to binary trees; each node has a maximum of 4 children instead of 2 children. It decomposes two-dimensional space by recursively subdividing it into four quadrants or regions, and each leaf cell represents “a unit of interesting spatial information” such as an object in a 3D scene or a hospital in Google Maps.
Quadtrees usually have three characteristics:
- They decompose space (geometric data, spatial information)
- Each cell/bucket/node has a maximum capacity of N children. When the capacity is reached, the cell splits into more high-definition cells.
- The tree follows the spatial decomposition of the quadtree
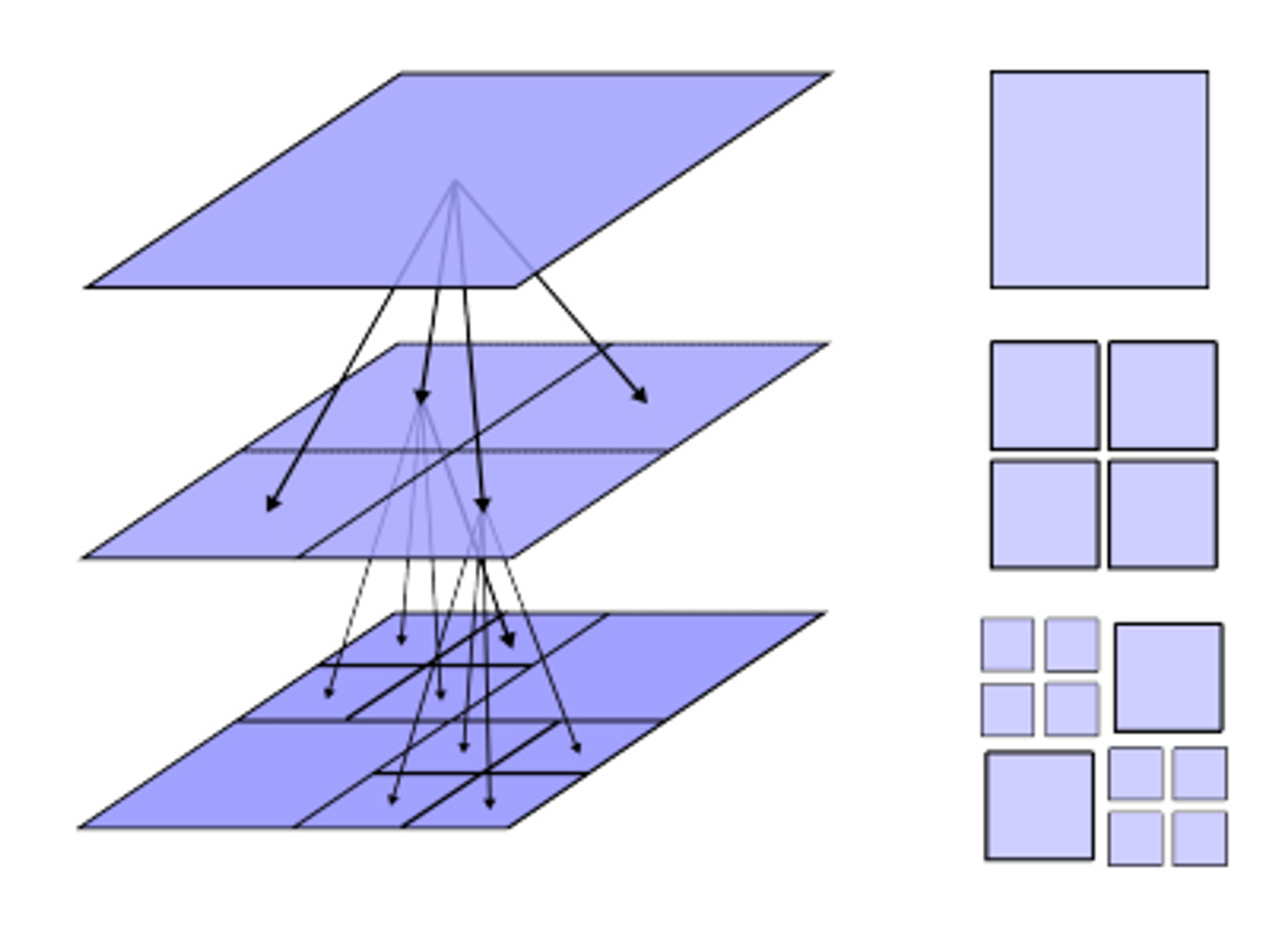
Why use a quadtree? Say that you needed to find a point p in an MxN space; finding the quadrant the point is in around O(logN) time (think binary search but with 4 variables).
Typically, quadtrees hold information about geometric primitives. This is the primary use case in spatial data storage/databases (which is a general-purpose database that has been enhanced to represent objects defined in a geometric space). The primitives could be lines, points, or polygons, and each leaf could hold information about a vector or point in the geometric space. For instance, if I had a unit cube stored in a spatial database, if I wanted to query the point at (1,1,1), I would query the highest definition leaf in the quadtree. If I wanted information about the plane at y=1, I would then query from the layer below the root node, which contains information about the whole cube.
Quadtrees are used much more commonly in computer graphics, such as for image rasterization. When we have an image but need to save memory without reducing overall quality, quadtrees are a relatively lossless compression method. A typical algorithm to do this is to:
- Divide the image into quadrants until each quadrant represents a simple pixel. Each node stores the average color of each region it represents.
- Traverse the quadtree and encode each leaf and node with the appropriate color value. Pixel-level leaf nodes should store the color of the pixel, and nodes higher in the hierarchy should store the average of its children’s values.
- Decode the data back into the quadtree, recursively building the tree by reading in each node’s children and the node’s values. If the encoded data or the average of the values is less than a certain threshold (determines how compressed an image can get), the node becomes a leaf and a compressed, larger area of spatial color data is saved into the tree.
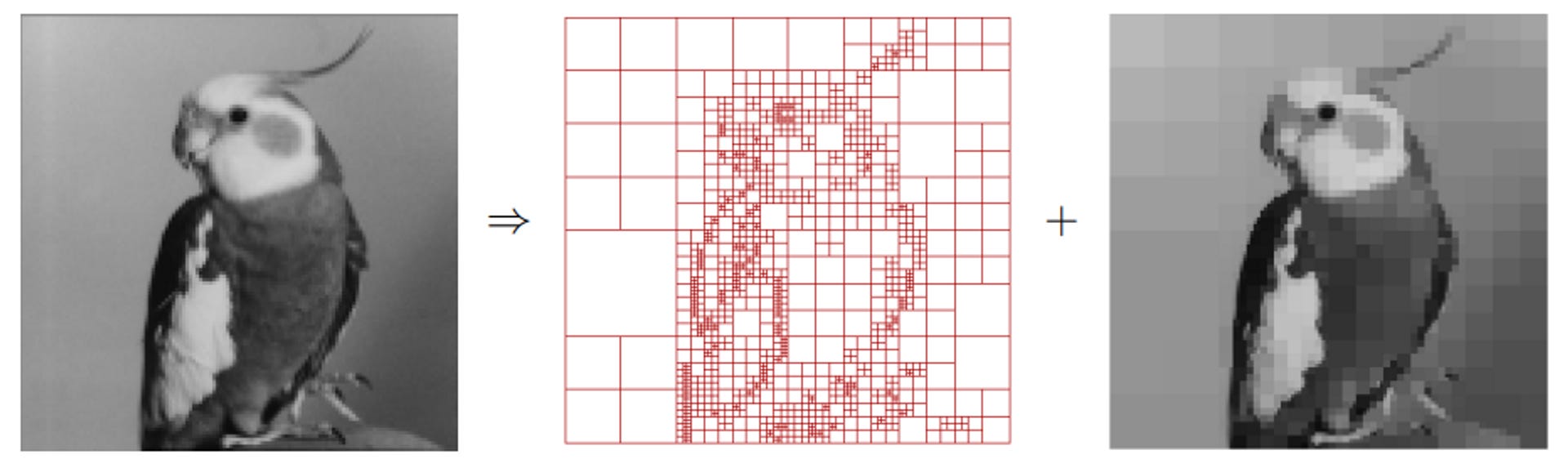
This method is great for rastering vector graphics, using the vector’s coverage in each quadrant to determine its presence in the final raster.
With computer vision ML applications, quadtrees are great for image processing and feature detection. Image compression can remove a lot of the noise in images, cleaning up the image before and after edge detection. Methods like Canny Edge Detection often have Gaussian filters and Sobel operator passes to remove noise and unconfident edges. However, sometimes images could be quite large and image compression through quadtrees could remove a lot of matrix operations in preprocessing. After edges have been found, there often are areas of noisy edges. These could be removed with hysteresis and hough transforms; quadtrees could also effectively encode which edges are important features for analysis.
In computer vision, feature detection is a method of identifying distinctive patterns or points of interest in an image, which is used as a basis for further analysis (such as identifying animals in an image or detecting types of fabric on a jacket).
Quadtrees could be used for adaptive scale analysis, which means that feature detection algorithms can analyze different regions of the image at different scales. This allows for robust testing of the algorithm, as well as recursive feature-matching algorithms. For instance, if we had two images A and B, and we wanted to find the corresponding landmarks between the images, we can first use a feature detection algorithm at higher definition nodes (such as the Harris corner detector) and a descriptor is computed at each keypoint. This describes the local image information around the point, such as gradients or the intensities of the pixels within a certain region. Quadtrees could be constructed to have the keypoints at the leaf nodes and then used to match keypoints between image A and image B. This can narrow down the search space in image B. Once the region is identified, we can compare the similarity of the keypoint descriptors through cosine similarity or Euclidean distance metrics. Based on a predefined threshold, correspondences can be created between the two images, and applications such as image-stitching and object recognition can be enabled.
Texture analysis could be done in the same fashion, by encoding some features, such as a frequency domain analysis through an FFT, into nodes, and using quadtree decomposition to analyze groups of texture patterns using ML algorithms. Since the data is organized like this, it is easier for ML models, such as convolutional neural networks, to help with feature extraction.
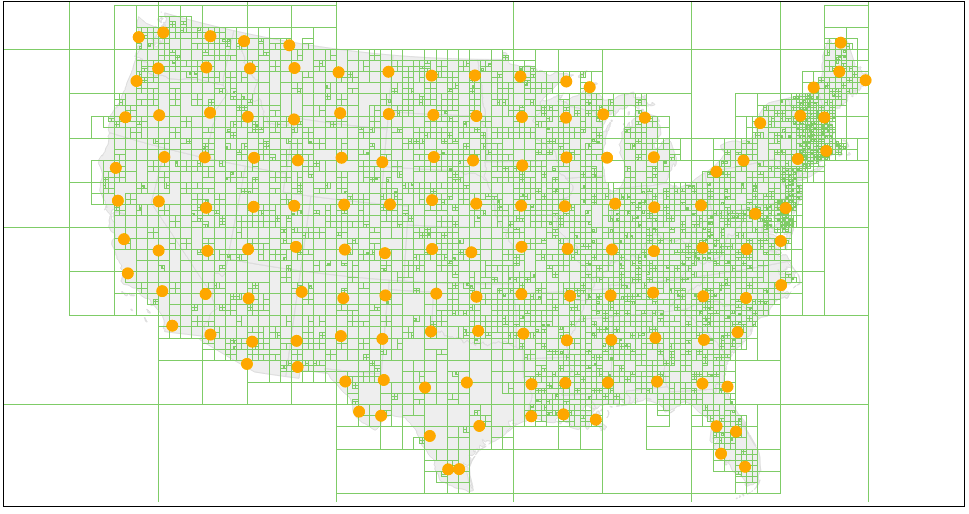
Geohashing is another use case of quadtrees; coordinates and metadata of locations are hashed into a string and stored in a quadtree data structure to be queried through spatial indexing. Applications like ArcGIS and Google Maps use geohashing for querying and storing spatial data. Although ArcGIS uses R-trees (another data structure), Google Maps historically has used quadtrees. Each node of the quadtree stores a certain amount of information about a bounding box. Each bounding box is defined by the NE, NW, SE, and SW coordinates, which could be the screen/window of the map you see in a browser or app window. When you finish moving around in the application, a quadtree is reconstructed in the bounding box, revealing markers and data up to a certain level of definition, such as city names and interstates down to house icons. By organizing the level of abstraction at this level, querying can be faster and reduce information clutter depending on the viewpoint bounding box.
Gaming and computer graphics is where quadtrees really shine. In 2D collision systems, such as in player GUIs, light systems, and sprite collisions. For many games, GUIs consist of elements such as text fields, buttons, radio buttons etc. Each could be interacted with through user selection, hovering, and clicking, as well as disabled and hidden. Quadtrees offer an efficient solution for hit-testing by dividing the screen into quadrants and associating GUI elements with the appropriate quadrants. When a user interacts with the screen, the system checks the relevant quadrant(s) to quickly identify the GUI elements under the mouse cursor or touch point that could be visible and interacted with. This reduces the search space and improves the responsiveness of the GUI.
2D collision checking can be done with quadtrees too. During gameplay, instead of performing a pairwise collision check between all sprites, the quadtree is queried to identify potential neighboring sprites in the same or adjacent quadrants. Only sprites within the same quadrant or nearby quadrants need to be checked for collisions, reducing the number of comparisons needed and improving the efficiency of collision detection. As sprites move or change positions, the quadtree is updated to reorganize the spatial distribution of sprites. This dynamic nature of quadtrees ensures that the collision detection process remains efficient as the game world evolves. Dynamic light sources can also employ quadtrees to effectively manage light sources. The quadtree can organize positions of the light sources in quadrants, and calculate nearby regions that would be affected by the light source.
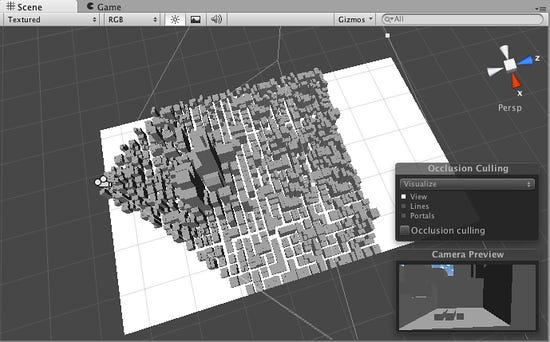
Moving into the 3D world, these ideas still stand with “octrees,” the same thing as a quadtree but for a 3D point space and partition the space into octants, rather than quadrants. A major application is in frustum culling, a technique used in 3D computer graphics to optimize rendering performance by eliminating objects that fall outside the view frustum. The view frustum is the portion of the 3D scene that is visible from the camera’s perspective. Objects that are entirely outside the frustum are not rendered, saving computational resources.
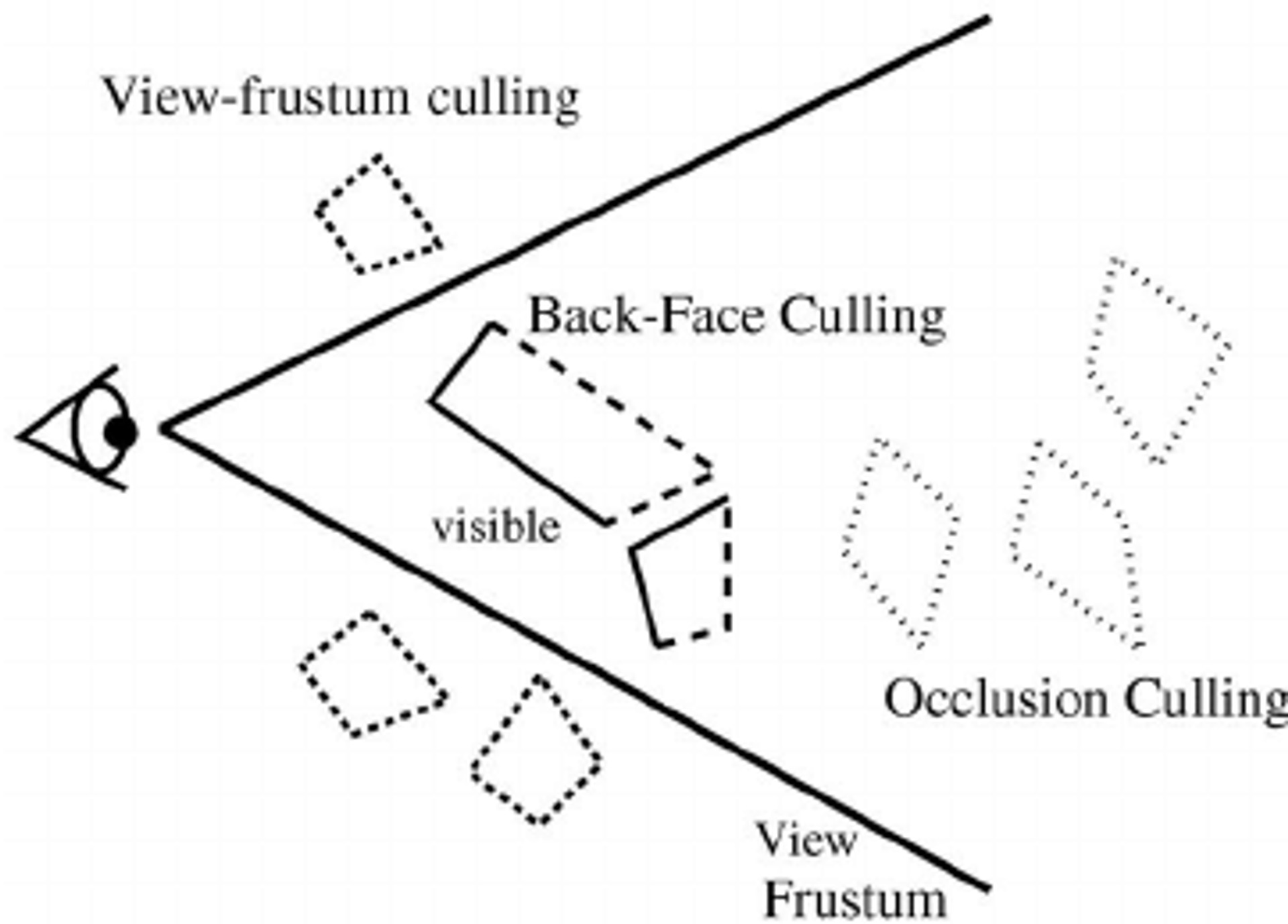
An octree is constructed to represent the objects in 3D space. To perform frustum culling, the octree is traversed recursively from the root node. At each level of the octree, the octants are tested to see if they intersect, are completely inside, or are entirely outside the view frustum from the main player camera. If an octant is entirely outside the frustum, all objects within that octant can be culled (excluded from rendering). Conversely, if an octant is entirely inside the frustum, all objects within that octant are guaranteed to be visible and can be rendered. A more detailed visibility test is performed for octants that intersect the frustum to determine if individual objects within those octants are visible from the camera’s perspective. This test might involve bounding volume checks, occlusion queries, or other spatial optimizations. This algorithm is often more personalized and can vary, depending on the engine and proprietary implementations. In the same vein, instanced meshes (loading in areas of the scene only in view) can be governed by octrees as well.
Quadtrees are a versatile and efficient data structure with applications spanning various domains, including graphics, games, 2D and 3D UI, and data storage. By leveraging their hierarchical nature and spatial partitioning capabilities, quadtrees enable fast queries and manipulations in large and dynamic datasets.